Primitive distributed publication via a Google hack
I've done some simple experiments to see if we could hijack Google as a rich link harvester for Interarchive. As reported earlier on this list, I was disappointed to find that Google's API doesn't really enable more structure to search queries than the Advanced Search option. So, inspired by a suggestion of former student Chris Vaughan, I concocted a simple test to see what could be accomplished using just the "allinanchor" option, which inspects text inside anchor tags on Web pages.
The idea is to slip rich link data inside anchor tags using a format that Google can see but Web browsers can't: a hidden span tag. I modified several Web pages that I knew Google spidered more or less regularly, changing links like this:
The <a href="ume_vote">site</a>includes election information....
into links like this:
The <a href="ume_vote"><span style="display: none">dp_politics dp_network dp_community</span></a> includes election information....
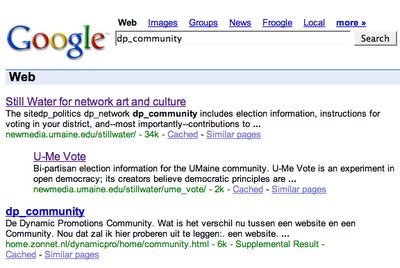
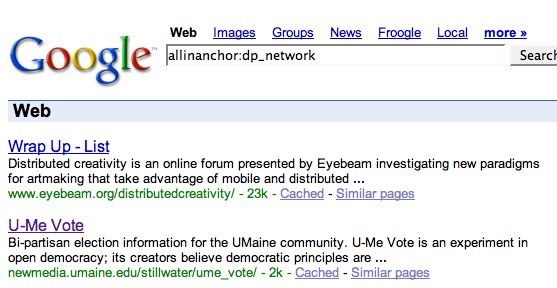
I had to wait a week or so for GoogleBot to spider these new pages, but the results are promising:When I searched for these hidden metadata tags, Google returned not the linking page, but the pages that it linked to. For example, in the Still Water home page I hid "dp_network" tags in links to Eyebeam and U-Me Vote; these two latter pages showed up in a Google search for "allinanchor:dp_network". (See figure 1). When I used this same technique to embed a tag called "dp_community", the site I linked to appeared but also the page that did the linking. (See figure 2.) At first I was confused by this, because although GoogleBot seems to harvest hidden text, PageRank tends to omit it from search returns--because it can be used by spammers to direct people searching for "car" to porn sites, etc.
When I used this same technique to embed a tag called "dp_community", the site I linked to appeared but also the page that did the linking. (See figure 2.) At first I was confused by this, because although GoogleBot seems to harvest hidden text, PageRank tends to omit it from search returns--because it can be used by spammers to direct people searching for "car" to porn sites, etc.
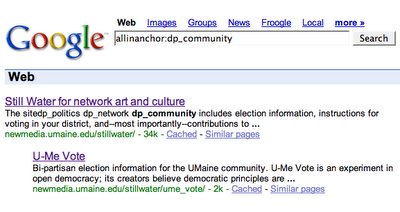
Then I did a search on "dp_community" by itself and found that it is actually a name used in cleartext on other Web sites! (See figure 3.) So that's why I think Google returned it differently from "dp_network." (I'll have to come up with a more idiosyncratic prefix than dp_ ;)
To conclude, this sneaky way of tagging external sites via rich links seems to work as a discovery tool ("Show me a list of Web pages related to the concept of *network*.")
Unfortunately, I haven't figured out a way to return anything better using this technique than a list of sites sorted by Google PageRank. To do statistics on this sort of linking, and thus to generate anything resembling an influence cloud, may require some kind of registration in a database. More about this in a future post.
jon
The idea is to slip rich link data inside anchor tags using a format that Google can see but Web browsers can't: a hidden span tag. I modified several Web pages that I knew Google spidered more or less regularly, changing links like this:
The <a href="ume_vote">site</a>includes election information....
into links like this:
The <a href="ume_vote"><span style="display: none">dp_politics dp_network dp_community</span></a> includes election information....
I had to wait a week or so for GoogleBot to spider these new pages, but the results are promising:When I searched for these hidden metadata tags, Google returned not the linking page, but the pages that it linked to. For example, in the Still Water home page I hid "dp_network" tags in links to Eyebeam and U-Me Vote; these two latter pages showed up in a Google search for "allinanchor:dp_network". (See figure 1).
 When I used this same technique to embed a tag called "dp_community", the site I linked to appeared but also the page that did the linking. (See figure 2.) At first I was confused by this, because although GoogleBot seems to harvest hidden text, PageRank tends to omit it from search returns--because it can be used by spammers to direct people searching for "car" to porn sites, etc.
When I used this same technique to embed a tag called "dp_community", the site I linked to appeared but also the page that did the linking. (See figure 2.) At first I was confused by this, because although GoogleBot seems to harvest hidden text, PageRank tends to omit it from search returns--because it can be used by spammers to direct people searching for "car" to porn sites, etc.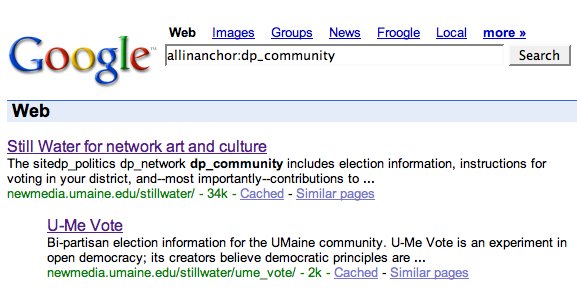
Then I did a search on "dp_community" by itself and found that it is actually a name used in cleartext on other Web sites! (See figure 3.) So that's why I think Google returned it differently from "dp_network." (I'll have to come up with a more idiosyncratic prefix than dp_ ;)

To conclude, this sneaky way of tagging external sites via rich links seems to work as a discovery tool ("Show me a list of Web pages related to the concept of *network*.")
Unfortunately, I haven't figured out a way to return anything better using this technique than a list of sites sorted by Google PageRank. To do statistics on this sort of linking, and thus to generate anything resembling an influence cloud, may require some kind of registration in a database. More about this in a future post.
jon
posted by Jon Ippolito at 11:10 AM
![]()
![]()


0 Comments:
Post a Comment
<< Home